Optimizers in Deep Learning

What is Optimizers?
Optimizers are algorithms used to reduce the loss function and update the weights in backpropagation.
Here is the formula used by all the optimizers for updating the weights with a certain value of the learning rate.

Types of Optimizers
1. Gradient Descent
This is the most common optimizer used in neural networks. The weights are updated when the whole dataset gradient is calculated, If there is a huge amount of data weights updation takes more time and required huge amount of RAM size memory which will slow down the process and computationally expensive.

There is also a saddle point problem. This is a point where the gradient is zero but is not an optimal point.
In some cases, problems like Vanishing Gradient or Exploding Gradient may also occur due to incorrect parameter initialization.
These problems occur due to a very small or very large gradient, which makes it difficult for the algorithm to converge. To solve this we use Stochastic GD
2. Stochastic Gradient Descent

Instead of taking entire data at one time, in SGD we take single record at a time to feed neural network and to update weights.
SGD is updated only once, there is no redundancy, it is faster than GD, and less computationally expensive.
SGD is updated more frequently, the cost function will have severe oscillations as we can see in the figure. The oscillation of SGD may jump to a better local minimum.
3. Mini-Batch Gradient Descent

MBGD uses where the model parameters are updated in n small batch sizes, n samples to calculate each time. This results in less memory usage and low variance in the model.
If the learning rate is too small, the convergence rate will be slow. If it is. too. large, the loss function will oscillate or even deviate at the minimum value.
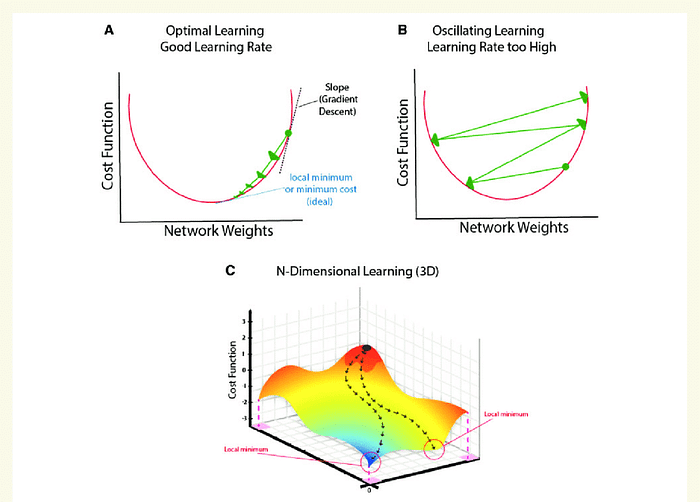
Reason for producing Noise because we don’t know the whole data and we taking batch of data so it takes more time compare to GD. To reduce the noise we use SGD With Momentum
4. SGD With Momentum
SGD with momentum is method which helps accelerate gradients vectors in the right directions, thus leading to faster converging and reduce the noise.
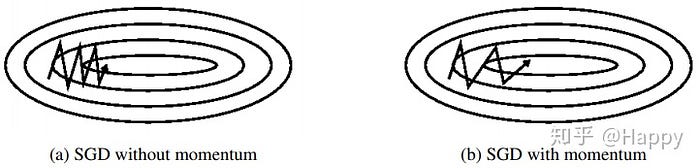
To make curve smooth we use Exponentially weighed averages
For complete math behind SGD with momentum refer:
Stochastic Gradient Descent with momentum | by Vitaly Bushaev | Towards Data Science
5. Adaptive Gradient optimization
Adagrad GD is a modified stochastic gradient descent with per-parameter learning rate. Learning rate is important hyper-parameter varying this can change the pace of training.
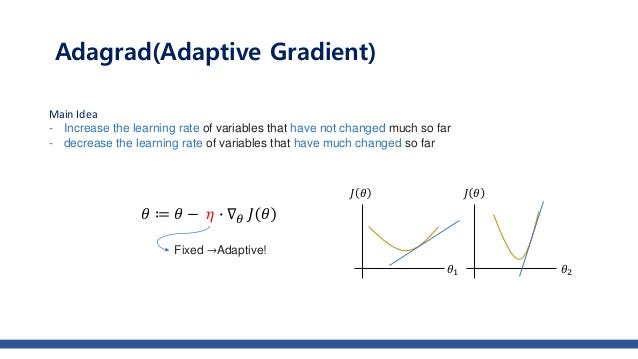

So at each iteration, first the S at time t will be calculated and as the iterations increase the value of t increases, and thus S t will start increasing and it makes the learning rate to decrease gradually so it leading to no change between the new and the old weight. This in turn causes the learning rate to shrink and eventually become very small, where the algorithm is not able to acquire any further knowledge.
6. RMSprop / Adadelta
(Root Mean Square Propagation)It is an improvement to the Adagrad optimizer. However, both use the same method which utilizes an Exponential Weighted Average to determine the learning rate at time t for each iteration. It is suggested to set gamma at 0.95, as it has been showing good results for most of the cases.
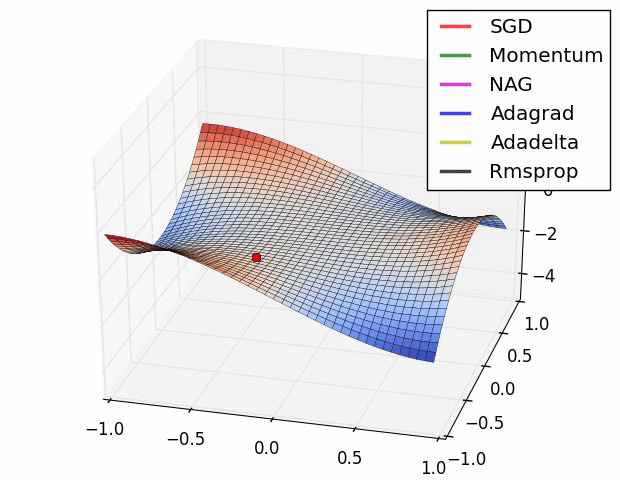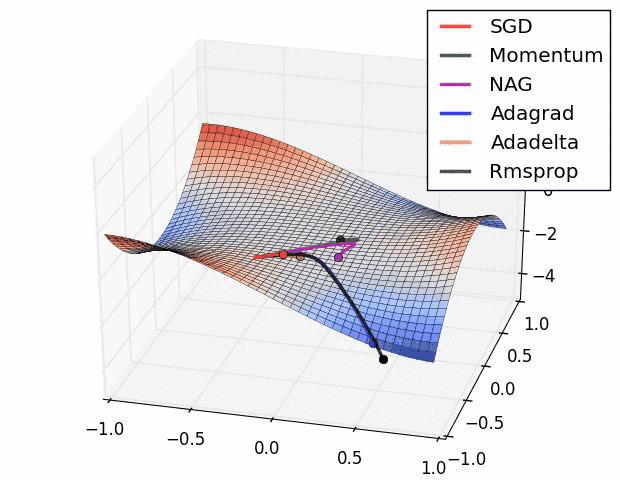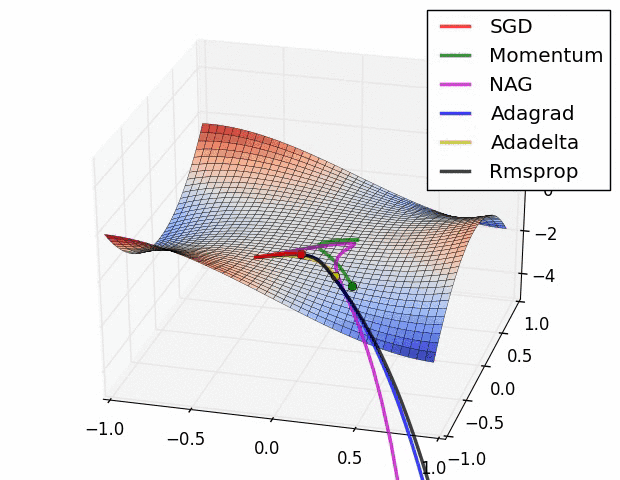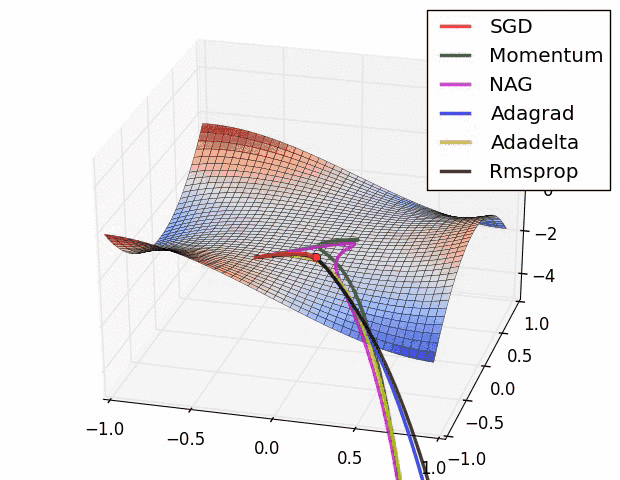
7. Adam Optimizer
Adaptive Moment Estimation it combines both RMSprop and and momentum-based GD. It is the most commonly used optimizer.
It has many benefits like low memory requirements, works best with large data and parameters with efficient computation.

It is proposed to have default values of β1=0.9 ,β2 = 0.999 and ε =10E-8. Studies show that Adam works well in practice, in comparison to other adaptive learning algorithms.
Please Follow me for more such articles on Deep Learning. Thanks for Reading.
